The aim of the processing chain is to extract, step by step, the elements needed to make a decision from the raw data. Once the noise has been removed, the filtered data is used to create coherent sets to feed the learning algorithms, which then use other coherent data sets to test performance.
Pre-treatment
We design your solution as a sequence of processes using a sequence of operators. Our representation is similar to that of an automaton.
An application is defined as a response to a problem in the form of a sequence of actions. Each action is performed in response to a specific situation, and it is the sequence of these actions that leads to the objective.
The classic operators are :
denoising,
filtering,
segmentation,
binarization.
We are experts in :
operator modeling,
optimization of operator chain parameters,
real-time implementation of a chain of operators.
Building learning sets
We call "Data Landscape" the set of data characterizing the problem to be solved.
Characterization is fundamental to understanding the topology of these landscapes, so that the right classification tools can be applied.
In addition, as infrastructures age slowly or break up abruptly, the landscape changes: data groups slide in relation to each other, rendering classification tools obsolete.
Not taking this variability of the data landscape into account translates into an increase in data classification:
Confusing measures
Ambiguity measures
Distance rejection measures
Our data set characterizations :
Factor analysis
Spectral analysis
Metric
Learning
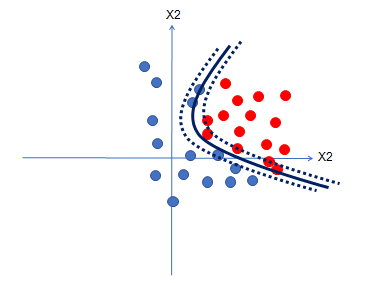
The data is now available in the form of a landscape, and we need to determine the homogeneous zones that form the categories that are the subject of the problem to be solved.
Learning consists in constructing these boundaries using a suitable algorithm; the strategy for presenting the data to the algorithm is fundamental to converge towards a successful generalization, and not to drift towards over-learning.
The result is a component in the form of a software brick representing the data set and the learning modalities.
We are specialists in all high-performance approaches such as :