La chaîne de traitement vise à extraire, étape par étape, les éléments nécessaires à la prise de décision à partir de la donnée brute. Après nettoyage des bruits, la donnée filtrée servira à constituer des ensembles cohérents pour alimenter les algorithmes d’apprentissage ; ces derniers utiliseront d’autres ensembles de données cohérents pour tester les performances.
Les pré-traitements
Nous concevons votre solution comme une suite de traitements à l’aide d’un enchainement d’opérateurs. Notre représentation se rapproche de celle d’un automate.
Une application est définie comme étant une réponse à un problème sous la forme d’une séquence d’actions. Chaque action est effectuée en réponse à une situation précise, et c’est l’enchainement de ces actions qui mène à l’objectif.
Les opérateurs classiques sont :
le débruitage,
le filtrage,
la segmentation,
la binarisation.
Nous sommes des experts dans :
la modélisation des opérateurs,
l’optimisation des paramètres d’une chaîne d’opérateurs,
la mise en œuvre temps réel d’une chaîne d’opérateurs.
Constitution d'ensembles d'apprentissage
Nous appelons “Paysage de données” l’ensemble des données caractérisant le problème à résoudre.
La caractérisation est fondamentale pour bien comprendre la topologie de ces paysages afin d’y associer les outils de classification ad-hoc.
Par ailleurs, avec le vieillissement lent ou les ruptures brutales des infrastructures, le paysage évolue : les groupes de données glissent les uns par rapport aux autres, rendant caduque les outils de classification.
Ne pas prendre en compte cette variabilité du paysage de données se traduit en termes de classement de ces données par une augmentation :
Des mesures de confusion
Des mesures d’ambiguité
Des mesures de rejet de distance
Nos caractérisations des ensembles de données :
Analyse factorielle
Analyse spectrale
Métriques
Les apprentissages
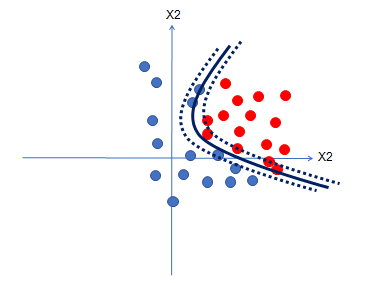
Les données sont à présent disponibles sous la forme d’un paysage ; on doit alors déterminer les zones homogènes qui forment des catégories, objet du problème à résoudre.
L’apprentissage consiste à construire ces frontières par un algorithme adapté ; la stratégie de présentation des données à l’algorithme est fondamentale pour converger vers une généralisation réussie, et on pas dériver vers du sur-apprentissage.
Il en résulte un composant sous la forme d’une brique logicielle représentative du jeu de données et des modalités de l’apprentissage.
Spécialistes, nous maîtrisons toutes les approches performantes comme :